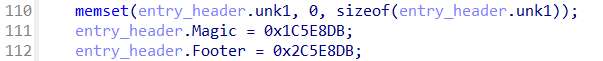In this blog post we will go into a user-friendly memory scanning Python library that was created out of the necessity of having more control during memory scanning. We will give an overview of how this library works, share the thought process and the why’s. This blog post will not cover the inner workings of the memory management of the respective platforms.
Memory scanning is the practice of iterating over the different processes running on a computer system and searching through their memory regions for a specific pattern. There can be a myriad of reasons to scan the memory of certain processes. The most common use cases are probably credential access (accessing the memory of the lsass.exe process for example), scanning for possible traces of malware and implants or recovery of interesting data, such as cryptographic material.
If time is as valuable to you as it is to us at Fox-IT, you probably noticed that performing a full memory scan looking for a pattern is a very time-consuming process, to say the least.
Why is scanning memory so time consuming when you know what you are looking for, and more importantly; how can this scanning process be sped up? While looking into different detection techniques to identify running Cobalt Strike beacons, we noticed something we could easily filter on, speeding up our scanning processes: memory attributes.
Memory attributes are comparable to the permission system we all know and love on our regular file and directory structures. The permission system dictates what kind of actions are allowed within a specific memory region and can be changed to different sets of attributes by their respective API calls.
The following memory attributes exist on both the Windows and UNIX platforms:
Read (R)
Write (W)
Execute (E)
The Windows platform has some extra permission attributes, plus quite an extensive list of allocation1 and protection2 attributes. These attributes can also be used to filter when looking for specific patterns within memory regions but are not important to go into right now.
So how do we leverage this information about attributes to speed up our scanning processes? It turns out that by filtering the regions to scan based on the memory attributes set for the regions, we can speed up our scanning process tremendously before even starting to look for our specified patterns.
Say for example we are looking for a specific byte pattern of an implant that is present in a certain memory region of a running process on the Windows platform. We already know what pattern we are looking for and we also know that the memory regions used by this specific implant are always set to:
Type
Protection
Initial
PRV
ERW
ERW
Table 1: Example of implant memory attributes that are set
Depending on what is running on the system, filtering on the above memory attributes already rules out a large portion of memory regions for most running processes on a Windows system.
If we take a notepad.exe process as an example, we can see that the different sections of the executable have their respective rights. The .text section of an executable contains executable code and is thus marked with the E permission as its protection:
If we were looking for just the sections and regions that are marked as being executable, we would only need to scan the .text section of the notepad.exe process. If we scan all the regions of every running process on the system, disregarding the memory attributes which are set, scanning for a pattern will take quite a bit longer.
We’ve incorporated the techniques described above into an easy to install Python package. The package is designed and tested to work on Linux and Microsoft Windows systems. Some of the notable features include:
Configurable scanning:
Scan all the process memory, specific processes by name or process identifier.
Regex and YARA support.
Support for user callback functions, define custom functions that execute routines when user specified conditions are met.
Easy to incorporate in bigger projects and scripts due to easy to use API.
The package was designed to be easily extensible by the end users, providing an API that can be leveraged to perform more.
Windows Defender (the antivirus shipped with standard installations of Windows) places malicious files into quarantine upon detection.
Reverse engineering mpengine.dll resulted in finding previously undocumented metadata in the Windows Defender quarantine folder that can be used for digital forensics and incident response.
Existing scripts that extract quarantined files do not process this metadata, even though it could be useful for analysis.
Fox-IT’s open-source digital forensics and incident response framework Dissect can now recover this metadata, in addition to recovering quarantined files from the Windows Defender quarantine folder.
dissect.cstruct allows us to use C-like structure definitions in Python, which enables easy continued research in other programming languages or reverse engineering in tools like IDA Pro.
Want to continue in IDA Pro? Just copy & paste the structure definitions!
During incident response engagements we often encounter antivirus applications that have rightfully triggered on malicious software that was deployed by threat actors. Most commonly we encounter this for Windows Defender, the antivirus solution that is shipped by default with Microsoft Windows. Windows Defender places malicious files in quarantine upon detection, so that the end user may decide to recover the file or delete it permanently. Threat actors, when faced with the detection capabilities of Defender, either disable the antivirus in its entirety or attempt to evade its detection.
The Windows Defender quarantine folder is valuable from the perspective of digital forensics and incident response (DFIR). First of all, it can reveal information about timestamps, locations and signatures of files that were detected by Windows Defender. Especially in scenarios where the threat actor has deleted the Windows Event logs, but left the quarantine folder intact, the quarantine folder is of great forensic value. Moreover, as the entire file is quarantined (so that the end user may choose to restore it), it is possible to recover files from quarantine for further reverse engineering and analysis.
While scripts already exist to recover files from the Defender quarantine folder, the purpose of much of the contents of this folder were previously unknown. We don’t like big unknowns, so we performed further research into the previously unknown metadata to see if we could uncover additional forensic traces.
Rather than just presenting our results, we’ve structured this blog to also describe the process to how we got there. Skip to the end if you are interested in the results rather than the technical details of reverse engineering Windows Defender.
In summary, whenever Defender puts a file into quarantine, it does three things:
A bunch of metadata pertaining to when, why and how the file was quarantined is held in a QuarantineEntry. This QuarantineEntry is RC4-encrypted and saved to disk in the /ProgramData/Microsoft/Windows Defender/Quarantine/Entries folder.
The contents of the malicious file is stored in a QuarantineEntryResourceData file, which is also RC4-encrypted and saved to disk in the /ProgramData/Microsoft/Windows Defender/Quarantine/ResourceData folder.
Within the /ProgramData/Microsoft/Windows Defender/Quarantine/Resource folder, a Resource file is made. Both from previous research as well as from our own findings during reverse engineering, it appears this file contains no information that cannot be obtained from the QuarantineEntry and the QuarantineEntryResourceData files. Therefore, we ignore the Resource file for the remainder of this blog.
While previous scripts are able to recover some properties from the ResourceData and QuarantineEntry files, large segments of data were left unparsed, which gave us a hunch that additional forensic artefacts were yet to be discovered.
Windows Defender encrypts both the QuarantineEntry and the ResourceData files using a hardcoded RC4 key defined in mpengine.dll. This hardcoded key was initially published by Cuckoo and is paramount for the offline recovery of the quarantine folder.
Pivotting off of public scripts and Bauch’s whitepaper, we loaded mpengine.dll into IDA to further review how Windows Defender places a file into quarantine. Using the PDB available from the Microsoft symbol server, we get a head start with some functions and structures already defined.
Recovering metadata by investigating the QuarantineEntry file#
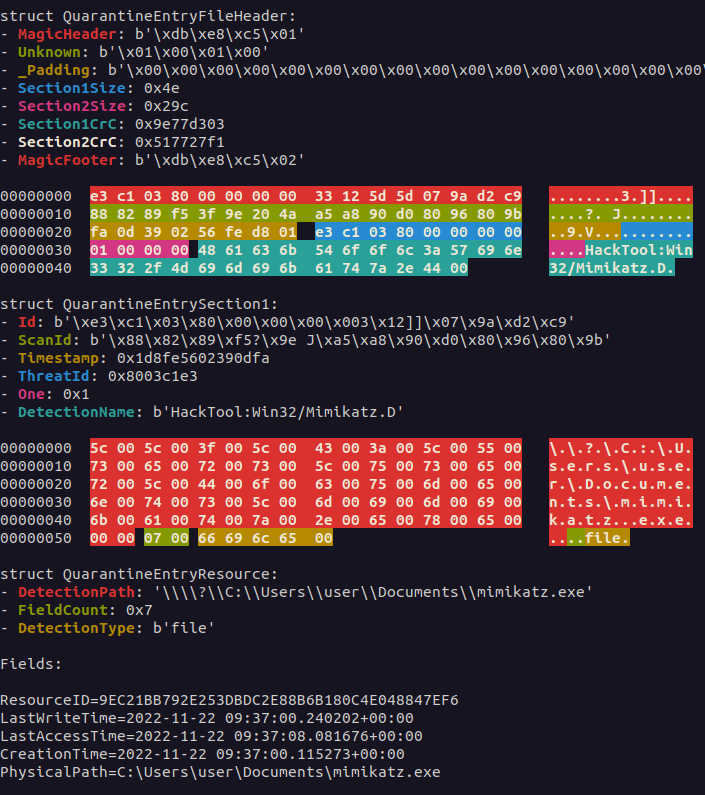
Let us begin with the QuarantineEntry file. From this file, we would like to recover as much of the QuarantineEntry structure as possible, as this holds all kinds of valuable metadata. The QuarantineEntry file is not encrypted as one RC4 cipherstream, but consists of three chunks that are each individually encrypted using RC4.
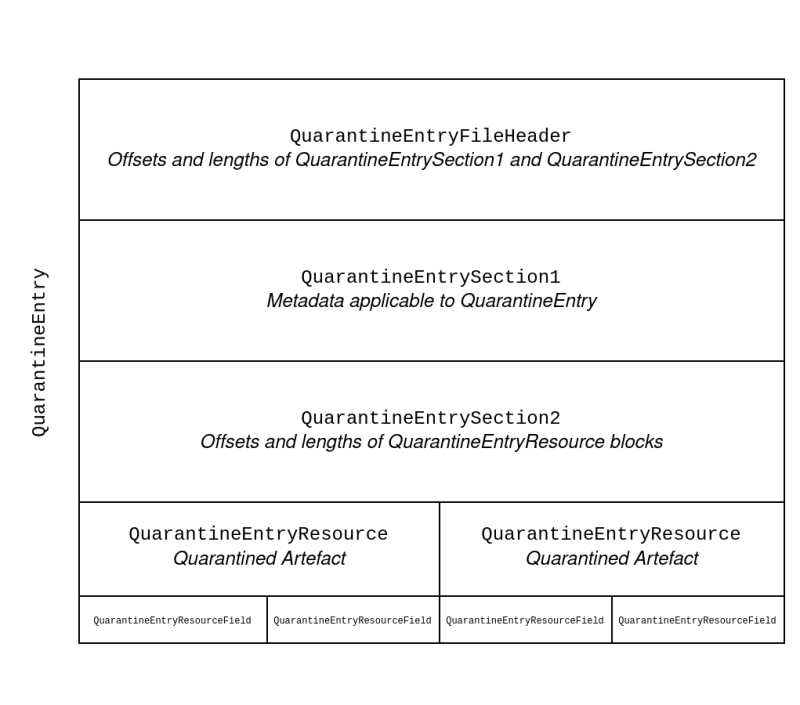
These three chunks are what we have come to call QuarantineEntryFileHeader, QuarantineEntrySection1 and QuarantineEntrySection2.
QuarantineEntryFileHeader describes the size of QuarantineEntrySection1 and QuarantineEntrySection2, and contains CRC checksums for both sections.
QuarantineEntrySection1 contains valuable metadata that applies to all QuarantineEntryResource instances within this QuarantineEntry file, such as the DetectionName and the ScanId associated with the quarantine action.
QuarantineEntrySection2 denotes the length and offset of every QuarantineEntryResource instance within this QuarantineEntry file so that they can be correctly parsed individually.
A QuarantineEntry has one or more QuarantineEntryResource instances associated with it. This contains additional information such as the path of the quarantined artefact, and the type of artefact that has been quarantined (e.g. regkey or file).
An overview of the different structures within QuarantineEntry is provided in Figure 1:
Figure 1: An example overview of a QuarantineEntry. In this example, two files were simultaneously quarantined by Windows Defender. Hence, there are two QuarantineEntryResource structures contained within this single QuarantineEntry.
As QuarantineEntryFileHeader is mostly a structure that describes how QuarantineEntrySection1 and QuarantineEntrySection2 should be parsed, we will first look into what those two consist of.
When reviewing mpengine.dll within IDA, the contents of both QuarantineEntrySection1 and QuarantineEntrySection2 appear to be determined in the
QexQuarantine::CQexQuaEntry::Commit function.
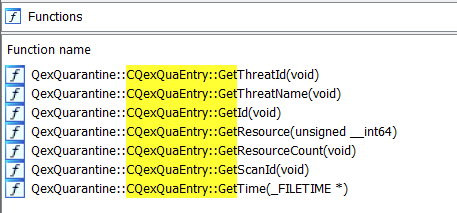
The function receives an instance of the QexQuarantine::CQexQuaEntry class. Unfortunately, the PDB file that Microsoft provides for mpengine.dll does not contain contents for this structure. Most fields could, however, be derived using the function names in the PDB that are associated with the CQexQuaEntry class:
Figure 2: Functions retrieving properties from QuarantineEntry.
The Id, ScanId, ThreatId, ThreatName and Time fields are most important, as these will be written to the QuarantineEntry file.
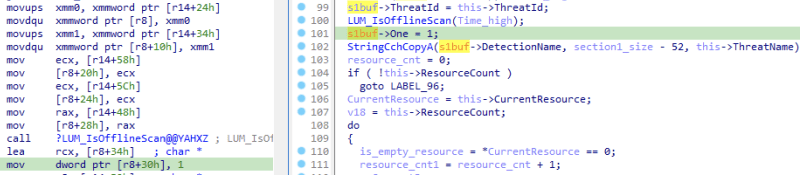
At the start of the QexQuarantine::CQexQuaEntry::Commit function, the size of Section1 is determined.
Figure 3: Reviewing the decompiled output of CqExQuaEntry::Commit shows the size of QuarantineEntrySection1 being set to the length of ThreatName plus 53.
This sets section1_size to a value of the length of the ThreatName variable plus 53. We can determine what these additional 53 bytes consist of by looking at what values are set in the QexQuarantine::CQexQuaEntry::Commit function for the Section1 buffer.
This took some experimentation and required trying different fields, offsets and sizes for the QuarantineEntrySection1 structure within IDA. After every change, we would review what these changes would do to the decompiled IDA view of the QexQuarantine::CQexQuaEntry::Commit function.
Some trial and error landed us the following structure definition:
While reviewing the final decompiled output (right) for the assembly code (left), we noticed a field always being set to 1:
Figure 4: A field of QuarantineEntrySection1 always being set to the value of 1.
Given that we do not know what this field is used for, we opted to name the field ‘One’ for now. Most likely, it’s a boolean value that is always true within the context of the QexQuarantine::CQexQuaEntry::Commit commit function.
Now that we have a structure definition for the first section of a QuarantineEntry, we now move on to the second part. QuarantineEntrySection2 holds the number of QuarantineEntryResource objects confined within a QuarantineEntry, as well as the offsets into the QuarantineEntry structure where they are located.
In most scenarios, one threat gets detected at a time, and one QuarantineEntry will be associated with one QuarantineEntryResource. This is not always the case: for example, if one unpacks a ZIP folder that contains multiple malicious files, Windows Defender might place them all into quarantine. Each individual malicious file of the ZIP would then be one QuarantineEntryResource, but they are all confined within one QuarantineEntry.
To be able to parse QuarantineEntryResource instances, we look into the CQexQuaResource::ToBinary function. This function receives a QuarantineEntryResource object, as well as a pointer to a buffer to which it needs to write the binary output to. If we can reverse the logic within this function, we can convert the binary output back into a parsed instance during forensic recovery.
Looking into the CQexQuaResource::ToBinary function, we see two very similar loops as to what was observed before for serializing the ThreatName of QuarantineEntrySection1. By reviewing various decrypted QuarantineEntry files, it quickly became apparent that these loops are responsible for reserving space in the output buffer for DetectionPath and DetectionType, with DetectionPath being UTF-16 encoded:
Figure 5: Reservation of space for DetectionPath and DetectionType at the beginning of CQexQuaResource::ToBinary.
When reviewing the QexQuarantine::CQexQuaEntry::Commit function, we observed an interesting loop that (after investigating function calls and renaming variables) explains the data that is stored between the DetectionType and DetectionPath:
Figure 6: Alignment logic for serializing Fields.
It appears QuarantineEntryResource structures have one or more QuarantineResourceField instances associated with them, with the number of fields associated with a QuarantineEntryResource being stored in a single byte in between the DetectionPath and DetectionType. When saving the QuarantineEntry to disk, fields have an alignment of 4 bytes. We could not find mentions of QuarantineEntryResourceField structures in prior Windows Defender research, even though they can hold valuable information.
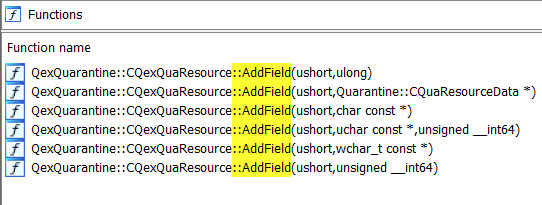
The CQExQuaResource class has several different implementations of AddField, accepting different kinds of parameters. Reviewing these functions showed that fields have an Identifier, Type, and a buffer Data with a size of Size, resulting in a simple TLV-like format:
To understand what kinds of types and identifiers are possible, we delve further into the different versions of the AddField functions, which all accept a different data type:
Figure 7: Finding different field types based on different implementations of the CqExQuaResource::AddField function.
Visiting these functions, we reviewed the Type and Size variables to understand the different possible types of fields that can be set for QuarantineResource instances. This yields the following FIELD_TYPE enum:
As the AddField functions are part of a virtual function table (vtable) of the CQexQuaResource class, we cannot trivially find all places where the AddField function is called, as they are not directly called (which would yield an xref in IDA). Therefore, we have not exhausted all code paths leading to a call of AddField to identify all possible Identifier values and how they are used. Our research yielded the following field identifiers as the most commonly observed, and of the most forensic value:
Especially CreationTime, LastAccessTime and LastWriteTime can provide crucial data points during an investigation.
Revisiting the QuarantineEntrySection2 and QuarantineEntryResource structures#
Now that we have an understanding of how fields work and how they are stored within the QuarantineEntryResource, we can derive the following structure for it:
Revisiting the QexQuarantine::CQexQuaEntry::Commit function, we can now understand how this function determines at which offset every QuarantineEntryResource is located within QuarantineEntry. Using these offsets, we will later be able to parse individual QuarantineEntryResource instances. Thus, the QuarantineEntrySection2 structure is fairly straightforward:
The last step for recovery of QuarantineEntry: the QuarantineEntryFileHeader#
Now that we have a proper understanding of the QuarantineEntry, we want to know how it ends up written to disk in encrypted form, so that we can properly parse the file upon forensic recovery. By inspecting the QexQuarantine::CQexQuaEntry::Commit function further, we can find how this ends up passing QuarantineSection1 and QuarantineSection2 to a function named CUserDatabase::Add.
We noted earlier that the QuarantineEntry contains three RC4-encrypted chunks. The first chunk of the file is created in the CUserDatabase::Add function, and is the QuarantineEntryHeader. The second chunk is QuarantineEntrySection1. The third chunk starts with QuarantineEntrySection2, followed by all QuarantineEntryResource structures and their 4-byte aligned QuarantineEntryResourceField structures.
We knew from Bauch’s work that the QuarantineEntryFileHeader has a static size of 60 bytes, and contains the size of QuarantineEntrySection1 and QuarantineEntrySection2. Thus, we need to decrypt the QuarantineEntryFileHeader first.
Based on Bauch’s work, we started with the following structure for QuarantineEntryFileHeader:
That leaves quite some bytes unknown though, so we went back to trusty IDA. Inspecting the CUserDatabase:Add function helps us further understand the QuarantineEntryHeader structure. For example, we can see the hardcoded magic header and footer:
Figure 8: Magic header and footer being set for the QuarantineEntryHeader.
A CRC checksum calculation can be seen for both the buffer of QuarantineEntrySection1 and QuarantineSection2:
Figure 9: CRC Checksum logic within CUserDatabase::Add.
These checksums can be used upon recovery to verify the validity of the file. The CUserDatabase:Add function then writes the three chunks in RC4-encrypted form to the QuarantineEntry file buffer.
Based on these findings of the magic header and footer and the CRC checksums, we can revise the structure definition for the QuarantineEntryFileHeader:
This was the last piece to be able to parse QuarantineEntry structures from their on-disk form. However, we do not want just the metadata: we want to recover the quarantined files as well.
Recovering files by investigating QuarantineEntryResourceData#
We can now correctly parse QuarantineEntry files, so it is time to turn our attention to the QuarantineEntryResourceData file. This file contains the RC4-encrypted contents of the file that has been placed into quarantine.
Let’s start by letting Windows Defender quarantine a Mimikatz executable and reviewing its output files in the quarantine folder. One would think that merely RC4 decrypting the QuarantineEntryResourceData file would result in the contents of the original file. However, a quick hexdump of a decrypted QuarantineEntryResourceData file shows us that there is more information contained within:
As visible in the hexdump, the MZ value (which is located at the beginning of the buffer of the Mimikatz executable) only starts at offset 0xCC. This gives reason to believe there is potentially valuable information preceding it.
There is also additional information at the end of the ResourceData file:
At the end of the hexdump, we see an additional buffer, which some may recognize as the “Zone Identifier”, or the “Mark of the Web”. As this Zone Identifier may tell you something about where a file originally came from, it is valuable for forensic investigations.
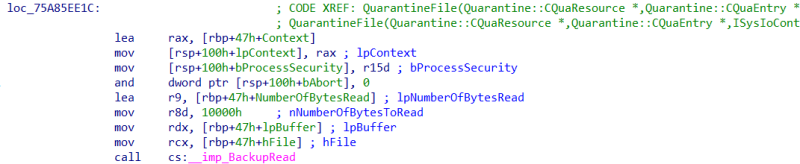
To understand where these additional buffers come from and how we can parse them, we again dive into the bowels of mpengine.dll. If we review the QuarantineFile function, we see that it receives a QuarantineEntryResource and QuarantineEntry as parameters. When following the code path, we see that the BackupRead function is called to write to a buffer of which we know that it will later be RC4-encrypted by Defender and written to the quarantine folder:
Figure 10: BackupRead being called within the QuarantineFile function.
A glance at the documentation of BackupRead reveals that this function returns a buffer seperated by Win32 stream IDs. The streams stored by BackupRead contain all data streams as well as security data about the owner and permissions of a file. On NTFS file systems, a file can have multiple data attributes or streams: the “main” unnamed data stream and optionally other named data streams, often referred to as “alternate data streams”. For example, the Zone Identifier is stored in a seperate Zone.Identifier data stream of a file. It makes sense that a function intended for backing up data preserves these alternate data streams as well.
The fact that BackupRead preserves these streams is also good news for forensic analysis. First of all, malicious payloads can be hidden in alternate data streams. Moreover, alternate datastreams such as the Zone Identifier and the security data can help to understand where a file has come from and what it contains. We just need to recover the streams as they have been saved by BackupRead!
Diving into IDA is not necessary, as the documentation tells us all that we need. For each data stream, the BackupRead function writes a WIN32_STREAM_ID to disk, which denotes (among other things) the size of the stream. Afterwards, it writes the data of the stream to the destination file and continues to the next stream. The WIN32_STREAM_ID structure definition is documented on the Microsoft Learn website:
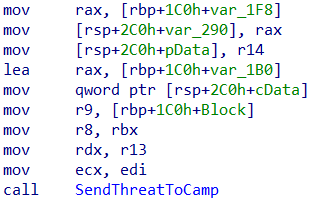
While reversing parts of mpengine.dll, we came across an interesting looking call in the HandleThreatDetection function. We appreciate that threats must be dealt with swiftly and with utmost discipline, but could not help but laugh at the curious choice of words when it came to naming this particular function.
Figure 11: A function call to SendThreatToCamp, a ‘call’ to action that seems pretty harsh.
We now have all structure definitions that we need to recover all metadata and quarantined files from the quarantine folder. There is only one step left: writing an implementation.
During incident response, we do not want to rely on scripts scattered across home directories and git repositories. This is why we integrate our research into Dissect.
We can leave all the boring stuff of parsing disks, volumes and evidence containers to Dissect, and write our implementation as a plugin to the framework. Thus, the only thing we need to do is parse the artefacts and feed the results back into the framework.
The dive into Windows Defender of the previous sections resulted in a number of structure definitions that we need to recover data from the Windows Defender quarantine folder. When making an implementation, we want our code to reflect these structure definitions as closely as possible, to make our code both readable and verifiable. This is where dissect.cstruct comes in. It can parse structure definitions and make them available in your Python code. This removes a lot of boilerplate code for parsing structures and greatly enhances the readability of your parser. Let’s review how easily we can parse a QuarantineEntry file using dissect.cstruct:
fromdissect.cstructimportcstructdefender_def="""
struct QuarantineEntryFileHeader {
CHAR MagicHeader[4];
CHAR Unknown[4];
CHAR _Padding[32];
DWORD Section1Size;
DWORD Section2Size;
DWORD Section1CRC;
DWORD Section2CRC;
CHAR MagicFooter[4];
};
struct QuarantineEntrySection1 {
CHAR Id[16];
CHAR ScanId[16];
QWORD Timestamp;
QWORD ThreatId;
DWORD One;
CHAR DetectionName[];
};
struct QuarantineEntrySection2 {
DWORD EntryCount;
DWORD EntryOffsets[EntryCount];
};
struct QuarantineEntryResource {
WCHAR DetectionPath[];
WORD FieldCount;
CHAR DetectionType[];
};
struct QuarantineEntryResourceField {
WORD Size;
WORD Identifier:12;
FIELD_TYPE Type:4;
CHAR Data[Size];
};
"""c_defender=cstruct()c_defender.load(defender_def)classQuarantineEntry:def__init__(self,fh:BinaryIO):# Decrypt & parse the header so that we know the section sizesself.header=c_defender.QuarantineEntryFileHeader(rc4_crypt(fh.read(60)))# Decrypt & parse Section 1. This will tell us some information about this quarantine entry.# These properties are shared for all quarantine entry resources associated with this quarantine entry.self.metadata=c_defender.QuarantineEntrySection1(rc4_crypt(fh.read(self.header.Section1Size)))# […]# The second section contains the number of quarantine entry resources contained in this quarantine entry,# as well as their offsets. After that, the individal quarantine entry resources start.resource_buf=BytesIO(rc4_crypt(fh.read(self.header.Section2Size)))
As you can see, when the structure format is known, parsing it is trivial using dissect.cstruct. The only caveat is that the QuarantineEntryFileHeader, QuarantineEntrySection1 and QuarantineEntrySection2 structures are individually encrypted using the hardcoded RC4 key. Because only the size of QuarantineEntryFileHeader is static (60 bytes), we parse that first and use the information contained in it to decrypt the other sections.
To parse the individual fields contained within the QuarantineEntryResource, we have to do a bit more work. We cannot add the QuarantineEntryResourceField directly to the QuarantineEntryResource structure definition within dissect.cstruct, as it currently does not support the type of alignment used by Windows Defender. However, it does support the QuarantineEntryResourceField structure definition, so all we have to do is follow the alignment logic that we saw in IDA:
# As the fields are aligned, we need to parse them individuallyoffset=fh.tell()for_inrange(field_count):# Alignoffset=(offset+3)&0xFFFFFFFCfh.seek(offset)# Parsefield=c_defender.QuarantineEntryResourceField(fh)self._add_field(field)# Move pointeroffset+=4+field.Size
We can use dissect.cstruct’s dumpstruct function to visualize our parsing to verify if we are correctly loading in all data:
And just like that, our parsing is done. Utilizing dissect.cstruct makes parsing structures much easier to understand and implement. This also facilitates rapid iteration: we have altered our structure definitions dozens of times during our research, which would have been pure pain without having the ability to blindly copy-paste structure definitions into our Python editor of choice.
Implementing the parser within the Dissect framework brings great advantages. We do not have to worry at all about the format in which the forensic evidence is provided. Implementing the Defender recovery as a Dissect plugin means it just works on standard forensic evidence formats such as E01 or ASDF, or against forensic packages the like of KAPE and Acquire, and even on a live virtual machine:
We hope to have shown that there can be great benefits to reverse engineering the internals of Microsoft Windows to discover forensic artifacts. By reverse engineering mpengine.dll, we were able to further understand how Windows Defender places detected files into quarantine. We could then use this knowledge to discover (meta)data that was previously not fully documented or understood. The main results of this are the recovery of more information about the original quarantined file, such as various timestamps and additional NTFS data streams, like the Zone.Identifier, which is information that can be useful in digital forensics or incident response investigations.
The documentation of QuarantineEntryResourceField was not available prior to this research and we hope others can use this to further investigate which fields are yet to be discovered. We have also documented how the BackupRead functionality is used by Defender to preserve the different data streams present in the NTFS file, including the Zone Identifier and Security Descriptor.
When writing our parser, using dissect.cstruct allowed us to tightly integrate our findings of reverse engineering in our parsing, enhancing the readability and verifiability of the code. This can in turn help others to pivot off of our research, just like we did when pivotting off of the research of others into the Windows Defender quarantine folder.
This research has been implemented as a plugin for the Dissect framework. This means that our parser can operate independently of the type of evidence it is being run against. This functionality has been added to dissect.target as of January 2nd 2023 and is installed with Dissect as of version 3.4.
Data acquisition during incident response engagements is always a big exercise, both for us and our clients. It’s rarely smooth sailing, and we usually encounter a hiccup or two. Fox-IT’s approach to enterprise scale incident response for the past few years has been to collect small forensic artefact packages using our internal data collection utility, “acquire”, usually deployed using the clients’ preferred method of software deployment. While this method works fine in most cases, we often encounter scenarios where deploying our software is tricky or downright impossible. For example, the client may not have appropriate software deployment methods or has fallen victim to ransomware, leaving the infrastructure in a state where mass software deployment has become impossible.
Many businesses have moved to the cloud, but most of our clients still have an on-premises infrastructure, usually in the form of virtual environments. The entire on-premises infrastructure might be running on a handful of physical machines, yet still restricted by the software deployment methods available within the virtual network. It feels like that should be easier, right? The entire infrastructure is running on one or two physical machines, can’t we just collect data straight from there?
Most of our clients who run virtualized environments use either VMware ESXi or Microsoft Hyper-V, with a slight bias towards ESXi. Hyper-V was considered the “easy” one between these two, so let’s first focus our attention towards ESXi.
VMware ESXi is one of the more popular virtualization platforms. Without going into too much premature detail on how everything works, it’s important to know that there are two primary components that make up an ESXi configuration: the hypervisor that runs virtual machines, and the datastore that stores all the files for virtual machines, like virtual disks. These datastores can be local storage or, more commonly, some form of network attached storage. ESXi datastores use VMware’s proprietary VMFS filesystem.
There are several challenges that we need to overcome to make this possible. What those challenges are depends on which concessions we’re willing to make with regards to ease of use and flexibility. I’m not one to back down from a challenge and not one to take unnecessary shortcuts that may come back to haunt me. Am I making this unnecessarily hard for myself? Perhaps. Will it pay off? Definitely.
The end goal is obvious, we want to be able to perform data acquisition on ideally live running virtual machines. Our internal data collection utility, “Acquire”, will play a key part in this. Acquire itself isn’t anything special, really. It builds on top of the Dissect framework, which is where all its power and flexibility comes from. Acquire itself is really nothing more than a small script that utilizes Dissect to read some files from a target and write it to someplace else. Ideally, we can utilize all this same tooling at the end of this.
So why not just run Acquire on the virtual machine files from an ESXi shell? Unfortunately, ESXi locks access to all virtual machine files while that virtual machine is running. You’d have to create full clones of every virtual machine you’d want to acquire, which takes up a lot of time and resources. This may be fine in small environments but becomes troublesome in environments with thousands of virtual machines or limited storage. We need some sort of offline access to these files.
We’ve already successfully done this in the past. However, those times took considerably more effort, time and resources and had their own set of issues. We would take a separate physical machine or virtual machine that was directly connected to the SAN where the ESXi datastores are located. We’d then use the open-source vmfs-tools or vmfs6-tools to gain access to the files on these datastores. Using this method, we’re bypassing any file locks that ESXi or VMFS may impose on us, and we can run acquire on the virtual disks without any issues.
Well, almost without any issues. Unfortunately, vmfs-tools and vmfs6-tools aren’t exactly proper VMFS implementations and routinely cause errors or data corruption. Any incident responder using vmfs-tools and vmfs6-tools will run into those issues sooner or later and will have to find a way to deal with them in the context of their investigation. This method also requires a lot of manual effort, resources and coordination. Far from an ideal “fire and forget” data collection solution.
We know that acquiring data directly from the datastore is possible, it’s just that our methods of accessing these datastores is very cumbersome. Can’t we somehow do all of this directly from an ESXi shell?
When using local or iSCSI network storage, ESXi also exposes the block devices of those datastores. While ESXi may put a lock on the files on a datastore, we can still read the on-device filesystem data just fine through these block devices. You can also run arbitrary executables on ESXi through its shell (except when using the execInstalledOnly configuration, or can you…? 😉), so this opens some possibilities to run acquisition software directly from the hypervisor.
Remember I said I liked a challenge? So far, everything has been relatively straightforward. We can just incorporate vmfs-tools into acquire and call it a day. Acquire and Dissect are pure Python, though, and incorporating some C library could overcomplicate things. We also mentioned the data corruption in vmfs-tools, which is something we ideally avoid. So what’s the next logical step? If you guessed “do it yourself” you are correct!
While vmfs-tools works for the most part, it lacks a lot of “correctness” with regards to the implementation. Much respect to anyone who has worked on these tools over the years, but it leaves a lot on the table as far as a reference implementation goes. For our purposes we have some higher requirements on the correctness of a filesystem implementation, so it’s worth spending some time working on one ourselves.
As part of an upcoming engagement, there just so happened to be some time available to work on this project. I open my trusty IDA Pro and get to work reverse engineering VMFS. I use vmfs-tools as a reference to get an idea of the structure of the filesystem, while reverse engineering everything else completely from scratch.
Simultaneously I work on reconstructing an ESXi system from its “offline” state. With Dissect, our preferred approach is to always work from the cleanest slate possible, even when dealing with a live system . For ESXi, this means that we don’t utilize anything from the “live” system, but instead will reconstruct this “live” state within Dissect ourselves from however ESXi stores its files when it’s turned off. This can cause an initial higher effort but pays of in the end because we can then interface with ESXi in any possible way with the same codebase: live by reading the block devices, or offline from reading a disk image.
This also brought its own set of implementation and reverse engineering challenges, which include:
Writing a FAT16 implementation, which ESXi uses for its bootbank filesystem.
Writing a vmtar implementation, a slightly customized tar file that is used for storing OS files (akin to VIBs).
Writing an Envelope implementation, a file encryption format that is used to encrypt system configuration on supported systems.
Figuring out how ESXi mounts and symlinks its “live” filesystem together.
Writing parsers for the various configuration file formats within ESXi.
After two weeks it’s time for the first trial run for this engagement. There are some initial missed edge cases, but a few quick iterations later and we’ve just performed our first live evidence acquisition through the hypervisor!
Now that we’ve achieved our goal on ESXi, let’s take a quick look to see what we need to do to achieve the same on Hyper-V. I mentioned earlier that Hyper-V was the easy one, and it really was. Hyper-V is just an extension of Windows, and we already know how to deal with Windows in Dissect and Acquire. We only need to figure out how to get and interpret information about virtual machines and we’re off to the races.
Hyper-V uses VHD or VHDX as its virtual disks. We already support that in Dissect, so nothing to do there. We need some metadata on where these virtual disks are located, as well as which virtual disks belong to a virtual machine. This is important, because we want a complete picture of a system for data acquisition. Not only to collect all filesystem artefacts (e.g. MFT or UsnJrnl of all filesystems), but also because important artefacts, like the Windows event logs, may be configured to store data on a different filesystem. We also want to know where to find all the registered virtual machines, so that no manual steps are required to run Acquire on all of them.
A little bit of research shows that information about virtual machines was historically stored in XML files, but any recent version of Hyper-V uses VMCX files, a proprietary file format. Never easy! For comparison, VMware stores this virtual machine metadata in a plaintext VMX file. Information about which virtual machines are present is stored in another VMCX file, located at C:\ProgramData\Microsoft\Windows\Hyper-V\data.vmcx. Before we’re able to progress, we must parse these VMCX files.
Nothing our trusty IDA Pro can’t solve! A few hours later we have a fully featured parser and can easily extract the necessary information out of these VMCX files. Just add a few lines of code in Dissect to interpret this information and we have fully automated virtual machine acquisition capabilities for Hyper-V!
The end result of all this work is that we can add a new capability to our Dissect toolbelt: hypervisor data acquisition. As a bonus, we can now also easily perform investigations on hypervisor systems with the same toolset!
There are of course some limitations to these methods, most of which are related to how the storage is configured. At the time of writing, our approach only works on local or iSCSI-based storage. Usage of vSAN or NFS are currently unsupported. Thankfully most of our clients use these supported methods, and research into improvements obviously never stops.
We initially mentioned scale and ease of deployment as a primary motivator, but other important factors are stealth and preservation of evidence. These seem to be often overlooked by recent trends in DFIR, but they’re still very important factors for us at Fox-IT. Especially when dealing with advanced threat actors, you want to be as stealthy as possible. Assuming your hypervisor isn’t compromised (😉), it doesn’t get much stealthier than performing data acquisition from the virtualization layer, while still maintaining some sense of scalability. This also achieves the ultimate preservation of evidence. Any new file you introduce or piece of software you execute contaminates your evidence, while also risking rollovers of evidence.
The last takeaway we want to mention is just how relatively easy all of this was. Sure, there was a lot of reverse engineering and writing filesystem implementations, but those are auxiliary tasks that you would have to perform regardless of the end goal. The important detail is that we only had to add a few lines of code to Dissect to have it all just… work. The immense flexibility of Dissect allows us to easily add “complex” capabilities like these with ease. All our analysts can continue to use the same tools they’re already used to, and we can employ all our existing analysis capabilities on these new platforms.
In the time between when this blog was written and published, Mandiant released excellent blog posts1,2 about malware targeting VMware ESXi, highlighting the importance of hypervisor forensics and incident response. We will also dive deeper into this topic with future blog posts.
Windows version up to at least version 7 contained a telemetry source called Customer Interaction Tracker
The CIT database can be parsed to aid forensic investigation
Finally, we also provide code to parse the CIT database yourself. We have implemented all of these findings into our investigation framework Dissect, which enables us to use them on all types of evidence data that we encounter
About 2 years ago while I was working on a large compromise assessment, I had extra time available to do a little research. For a compromise assessment, we take a forensic snapshot of everything that is in scope. This includes various log or SIEM sources, but also includes a lot of host data. This host data can vary from full disk images, such as those from virtual machines, to smaller, forensically acquired, evidence packages. During this particular compromise assessment, we had host data from about 10,000 machines. An excellent opportunity for large scale data analysis, but also a huge set of data to test new parsers on, or find less common edge cases for existing parsers! During these assignments we generally also take some time to look for new and interesting pieces of data to analyse. We don’t often have access to such a large and varied dataset, so we take advantage of it while we can.
Around this time I also happened to stumble upon the excellent blog posts from Maxim Suhanov over at dfir.ru. Something that caught my eye was his post about the CIT database in Windows. It may or may not stand for “Customer Interaction Tracker” and is one of the telemetry systems that exist within Windows, responsible for tracking interaction with the system and applications. I’d never heard of it before, and it seemed relatively unknown as his post was just about the only reference I could find about it. This, of course, piqued my interest, as it’s more fun exploring new and unknown data sources in contrast to well documented sources. And since I now had access to about 10k hosts, it seemed like as good a time as any to see if I could expore a little bit further than he had.
While Maxim does hypothesise about the purpose of the CIT database, he doesn’t describe much about how it is structured. It’s an LZNT1 compressed blob stored in the Windows registry at HKLM\Software\Microsoft\Windows NT\CurrentVersion\AppCompatFlags\CIT\System that, when decompressed, has some executable paths in there. Nothing seems to be known about how to parse this binary blob. So called “grep forensics”, while having its’ place, doesn’t scale, and you might be missing crucial pieces of information from the unparsed data. I’m also someone who takes comfort in knowing exactly how something is structured, without too many hypotheses and guesses.
In my large dataset I had plenty of CIT databases, so I could compare them and possibly spot patterns on how to parse this blob, so that’s exactly what I set out to do. Fast iteration with dissect.cstruct and a few hours of eyeballing hexdumps later, I came up with some structures on how I thought the data might be stored.
While still incredibly rough, I figured I had a rudimentary understanding of how the CIT was stored. However, at the time it was hardly a practical improvement over just “extracting the strings”, except perhaps that the parsing was a bit more efficient when compared to extracting strings. It did scratch initial my itch on figuring out how it might be stored, but I didn’t want to spend a lot more time on it at the time. I added it as a plugin in our investigation framework called dissect, ran it over all the host data we had and used it as an additional source of information during the remainder of the compromise assessment. I figured I’d revisit some other time.
Some other time turned out to be a lot farther into the future than I had anticipated. On an uneventful friday afternoon a few weeks ago, at the time of writing, and 2 years after my initial look, I figured I’d give the CIT another shot. This time I’d go about it with my usual approach, given that I had more time available now. That approach roughly consists of finding whatever DLL, driver or part of the Windows kernel is responsible for some behaviour, reverse engineering it and writing my own implementation. This is my preferred approach if I have a bit more time available, since it leaves little room for wrongful hypotheses and own interpretation, and grounds your implementation in mostly facts.
My usual approach starts with scraping the disk of one of my virtual machines with some byte pattern, usually a string in various encodings (UTF-8 and UTF-16-LE, the default string encoding in Windows, for example) in search of files that contain those strings or byte patterns. For this we can utilize our dissect framework that, among its many capabilities, allows us to easily search for occurrences of data within any data container, such as (sparse) VMDK files or other types of disk images. We can combine this with a filesystem parser to see if a hit is within the dataruns of a file, and report which files have hits. This process only takes a few minutes and I immediately get an overview of all the files on my entire filesystem that may have a reference to something I’m looking for.
In this case, I used part of the registry path where the CIT database is stored. Using this approach, I quickly found a couple of DLLs that looked interesting, but a quick inspection revealed only one that was truly of interest: generaltel.dll. This DLL, among other things, seems to be responsible for consuming the CIT database and its records, and emitting telemetry ETW messages.
Through reverse engineering the parsing code and looking at how the ETW messages are constructed, we can create some fairly complete looking structures to parse the CIT database.
typedefstruct_CIT_HEADER{WORDMajorVersion;WORDMinorVersion;DWORDSize;/* Size of the entire buffer */FILETIMECurrentTimeLocal;/* Maybe the time when the saved CIT was last updated? */DWORDCrc32;/* Crc32 of the entire buffer, skipping this field */DWORDEntrySize;DWORDEntryCount;DWORDEntryDataOffset;DWORDSystemDataSize;DWORDSystemDataOffset;DWORDBaseUseDataSize;DWORDBaseUseDataOffset;FILETIMEStartTimeLocal;/* Presumably when the aggregation started */FILETIMEPeriodStartLocal;/* Presumably the starting point of the aggregation period */DWORDAggregationPeriodInS;/* Presumably the duration over which this data was gathered
* Always 604800 (7 days) */DWORDBitPeriodInS;/* Presumably the amount of seconds a single bit represents
* Always 3600 (1 hour) */DWORDSingleBitmapSize;/* This appears to be the sizes of the Stats buffers, always 21 */DWORD_Unk0;/* Always 0x00000100? */DWORDHeaderSize;DWORD_Unk1;/* Always 0x00000000? */}CIT_HEADER;typedefstruct_CIT_PERSISTED{DWORDBitmapsOffset;/* Array of Offset and Size (DWORD, DWORD) */DWORDBitmapsSize;DWORDSpanStatsOffset;/* Array of Count and Duration (DWORD, DWORD) */DWORDSpanStatsSize;DWORDStatsOffset;/* Array of WORD */DWORDStatsSize;}CIT_PERSISTED;typedefstruct_CIT_ENTRY{DWORDProgramDataOffset;/* Offset to CIT_PROGRAM_DATA */DWORDUseDataOffset;/* Offset to CIT_PERSISTED */DWORDProgramDataSize;DWORDUseDataSize;}CIT_ENTRY;typedefstruct_CIT_PROGRAM_DATA{DWORDFilePathOffset;/* Offset to UTF-16-LE file path string */DWORDFilePathSize;/* strlen of string */DWORDCommandLineOffset;/* Offset to UTF-16-LE command line string */DWORDCommandLineSize;/* strlen of string */DWORDPeTimeDateStamp;/* aka Extra1 */DWORDPeCheckSum;/* aka Extra2 */DWORDExtra3;/* aka Extra3, some flag from PROCESSINFO struct */}CIT_PROGRAM_DATA;
When compared against the initial guessed structures, we can immediately get a feeling for the overall format of the CIT. Decompressed, the CIT is made up of a small header, a global “system use data”, a global “use data” and a bunch of entries. Each entry has its’ own “use data” as well as references to a file path and optional command line string.
Figuring out how to parse data is the easy part, interpreting this data is oftentimes much harder.
Looking at the structures we came up with, we have something called “use data” that contains some bitmaps, “stats” and “span stats”. Bitmaps are usually straightforward since there are only so many ways you can interpret those, but “stats” and “span stats” can mean just about anything. However, we still have the issue that the “system use data” has multiple bitmaps.
To more confidently interpet the data, it’s best we look at how it’s created. Further reverse engineering brings us to wink32base.sys, win32kfull.sys for newer Windows versions (e.g. Windows 10+), and win32k.sys for older Windows versions (e.g. Windows 7, Server 2012).
In the CIT header, we can see a BitPeriodInS, SingleBitmapSize and AggregationPeriodInS. With some values from a real header, we can confirm that (BitPeriodInS * 8) * SingleBitmapSize = AggregationPeriondInS. We also have a PeriodStartLocal field which is usually a nicely rounded timestamp. From this, we can make a fairly confident assumption that for every bit in the bitmap, the application in the entry or the system was used within a BitPeriodInS time window. This means that the bitmaps track activity over a larger time period in some period size, by default an hour. Reverse engineered code seems to support this, too. Note that all of this is in local time, not UTC.
For the “stats” or “span stats”, it’s not that easy. We have no indication of what these values might mean, other than their integer size. The parsing code seems to suggest they might be tuples, but that may very well be a compiler optimization. We at least know they aren’t offsets, since their values are often far larger than the size of the CIT.
Further reverse engineering win32k.sys seems to suggest that the “stats” are in fact individual counters, being incremented in functions such as CitSessionConnectChange, CitDesktopSwitch, etc. These functions get called from other relevant functions in win32k.sys, like xxxSwitchDesktop that calls CitDesktopSwitch. One of the smaller increment functions can be seen below as an example:
The increment events are different between the system use data and the program use data. If we map these increments out to the best of our ability, we end up with the following structures:
There are some interesting tracked statistics here, such as the amount of times someone logged on, locked their system, or how many times they clicked or pressed a key in an application.
We can see similar behaviour for “span stats”, but in this case it appears to be a pair of (count, duration). Similarly, if we map these increments out to the best of our ability, we end up with the following structures:
We can also identify that the single bitmap linked to each program entry is a bitmap of “foreground” activity for the aggregation period.
In the original source, I suspect these fields are accessed by index with an enum, but mapping them to structs makes for easier reverse engineering. You can also still see some unknowns in there, or unspecified fields such as Foreground0 and Foreground1. This is because the differentiation between these is currently unclear. For example, both counters might be incremented upon a foreground switch, but only one of them when a specific flag or condition is true. The exact condition or meaning of the flag is currently unknown.
During the reverse engineering of the various win32k modules, I noticed something disappointing: the CIT database seems to no longer exist in the same form on newer Windows versions. Some of the same code remains and some new code was introduced, but any relation to the stored CIT database as described up until now seems to no longer exists. Maybe it’s now handled somewhere else and I couldn’t find it, but I also haven’t encountered any recent Windows host that has had CIT data stored on it.
Something else seems to have taken its place, though. We have some stored DP and PUUActive (Post Update Use Info) data instead. If the running Windows version is a “multi-session SKU”, as determined by the RtlIsMultiSessionSku API, these values are stored under the key HKCU\Software\Microsoft\Windows NT\CurrentVersion\Winlogon. Otherwise, they are stored under HKLM\Software\Microsoft\Windows NT\CurrentVersion\AppCompatFlags\CIT.
We can apply the same technique here as we did with the older CIT database, which is to look at how ETW messages are being created from the data. A little bit of reversing later and we get the following structure:
I haven’t looked too deeply into the memoization shown here, but it’s largely irrelevant when parsing the data. We see some of the same fields we also saw in the PUU data, but also a ForegroundDurations array. This appears to be an array of foreground durations in milliseconds for a couple of hardcoded applications:
Each application is given an index in this array, starting from 1. Index 0 appears to be reserved for a cumulative time. It is not currently known if this list of applications changes between Windows versions. It’s also not currently known what “DP” stands for.
This information is stored at the registry key HKLM\Software\Microsoft\Windows NT\CurrentVersion\AppCompatFlags\CIT\win32k, under a subkey of some arbitrary version number. It contains values with the value name being the ImageFileName of the process, and the value being a flag indicating what types of messages or telemetry this application received during its lifetime. For example, the POWERBROADCAST flag is set if NtUserfnPOWERBROADCAST is called on a process, which itself it called from NtUserMessageCall. Presumably a system message if the power state of the system changed (e.g. a charger was plugged in). Currently known values are:
You can discover which events a process received by masking the stored value with these values. For example, the value 0x30000 can be interpreted as POWERBROADCAST|DEVICECHANGE, meaning that a process received those events.
This behaviour was only present in a Windows 7 win32k.sys and seems to no longer be present in more recent Windows versions. I have also seen instances where the values 4 and 8 were used, but have not been able to find a corresponding executable that produces these values. In most win32k.sys the code for this is inlined, but in some the function name AnswerTelemetryQuestion can be seen.
Another interesting registry key is HKLM\Software\Microsoft\Windows NT\CurrentVersion\AppCompatFlags\CIT\Module. It has subkeys for certain runtime DLLs (for example, System32/mrt100.dll or Microsoft.NET/Framework64/v4.0.30319/clr.dll), and each subkey has values for applications that have loaded this module. The name of the value is once again the ImageFileName and the value is a standard Windows timestamp of when the value was written.
These values are written by ahcache.sys, function CitmpLogUsageWorker. This function is called from CitmpLoadImageCallback, which subsequently is the callback function provided to PsSetLoadImageNotifyRoutine. The MSDN page for this function says that this call registers a “driver-supplied callback that is subsequently notified whenever an image is loaded (or mapped into memory)”. This callback checks a couple of conditions. First, it checks if the module is loaded from a system partition, by checking the DO_SYSTEM_SYSTEM_PARTITION flag of the underlying device. Then it checks if the image it’s loading is from a set of tracked modules. This list is optionally read from the registry key HKLM\System\CurrentControlSet\Control\Session Manager\AppCompatCache and value Citm, but has a default list to fall back to. The version of ahcache.sys that I analysed contained:
The tracked module path is concatenated to the aforementioned registry key to, for example, result in the key HKLM\Software\Microsoft\Windows NT\CurrentVersion\AppCompatFlags\CIT\Module\Microsoft.NET/Framework/v1.0.3705/mscorwks.dll. Note the replaced path separators to not conflict with the registry path separator. It does a final check if there are not more than 64 values already in this key, or if the ImageFileName of the executable exceeds 520 characters. In the first case, the current system time is stored in the OverflowQuota value. In the second case, the value name OverflowValue is used.
So far I haven’t found anything that actually removes values from this registry key, so OverflowQuota effectively contains the timestamp of the last execution to load that module, but which already had more than 64 values. If these values are indeed never removed, it unfortunately means that these registry keys only contain the first 64 executables to load these modules.
This behaviour seems to be present from Windows 10 onwards.
We showed how to parse the CIT database and provide some additional information on what it stores. The information presented may not be perfect, but this was just a couple of days worth of research into CIT. We hope it’s useful to some and perhaps also a showcase of a method to quickly research topics like these.
We also discovered the lack of the CIT database on newer Windows versions, and these new DP and PUUActive values. We provided some information on what these structures contain and structure definitions to easily parse them.
Finally, we also provide code to parse the CIT database yourself. It’s just the code to parse the CIT contents and doesn’t do anything to access the registry. There’s also no code to parse the other mentioned registry keys, since registry access is very implementation specific between investigation tools, and the values are quite trivial to parse out. We have implemented all of these findings into our investigation framework, which enables us to use them on all types of evidence data that we encounter.
We invite anyone curious on this topic to provide feedback and information for anything we may have missed or misinterpreted.
#!/usr/bin/env python3importarrayimportargparseimportioimportstructimportsysfrombinasciiimportcrc32fromdatetimeimportdatetime,timedelta,timezonetry:fromdissectimportcstructfromRegistryimportRegistryexceptImportError:print("Missing dependencies, run:\npip install dissect.cstruct python-registry")sys.exit(1)try:fromzoneinfoimportZoneInfoHAS_ZONEINFO=TrueexceptImportError:HAS_ZONEINFO=Falsecit_def="""
typedef QWORD FILETIME;
flag TELEMETRY_ANSWERS {
POWERBROADCAST = 0x10000,
DEVICECHANGE = 0x20000,
IME_CONTROL = 0x40000,
WINHELP = 0x80000,
};
typedef struct _CIT_HEADER {
WORD MajorVersion;
WORD MinorVersion;
DWORD Size; /* Size of the entire buffer */
FILETIME CurrentTimeLocal; /* Maybe the time when the saved CIT was last updated? */
DWORD Crc32; /* Crc32 of the entire buffer, skipping this field */
DWORD EntrySize;
DWORD EntryCount;
DWORD EntryDataOffset;
DWORD SystemDataSize;
DWORD SystemDataOffset;
DWORD BaseUseDataSize;
DWORD BaseUseDataOffset;
FILETIME StartTimeLocal; /* Presumably when the aggregation started */
FILETIME PeriodStartLocal; /* Presumably the starting point of the aggregation period */
DWORD AggregationPeriodInS; /* Presumably the duration over which this data was gathered
* Always 604800 (7 days) */
DWORD BitPeriodInS; /* Presumably the amount of seconds a single bit represents
* Always 3600 (1 hour) */
DWORD SingleBitmapSize; /* This appears to be the sizes of the Stats buffers, always 21 */
DWORD _Unk0; /* Always 0x00000100? */
DWORD HeaderSize;
DWORD _Unk1; /* Always 0x00000000? */
} CIT_HEADER;
typedef struct _CIT_PERSISTED {
DWORD BitmapsOffset; /* Array of Offset and Size (DWORD, DWORD) */
DWORD BitmapsSize;
DWORD SpanStatsOffset; /* Array of Count and Duration (DWORD, DWORD) */
DWORD SpanStatsSize;
DWORD StatsOffset; /* Array of WORD */
DWORD StatsSize;
} CIT_PERSISTED;
typedef struct _CIT_ENTRY {
DWORD ProgramDataOffset; /* Offset to CIT_PROGRAM_DATA */
DWORD UseDataOffset; /* Offset to CIT_PERSISTED */
DWORD ProgramDataSize;
DWORD UseDataSize;
} CIT_ENTRY;
typedef struct _CIT_PROGRAM_DATA {
DWORD FilePathOffset; /* Offset to UTF-16-LE file path string */
DWORD FilePathSize; /* strlen of string */
DWORD CommandLineOffset; /* Offset to UTF-16-LE command line string */
DWORD CommandLineSize; /* strlen of string */
DWORD PeTimeDateStamp; /* aka Extra1 */
DWORD PeCheckSum; /* aka Extra2 */
DWORD Extra3; /* aka Extra3, some flag from PROCESSINFO struct */
} CIT_PROGRAM_DATA;
typedef struct _CIT_BITMAP_ITEM {
DWORD Offset;
DWORD Size;
} CIT_BITMAP_ITEM;
typedef struct _CIT_SPAN_STAT_ITEM {
DWORD Count;
DWORD Duration;
} CIT_SPAN_STAT_ITEM;
typedef struct _CIT_SYSTEM_DATA_SPAN_STATS {
CIT_SPAN_STAT_ITEM ContextFlushes0;
CIT_SPAN_STAT_ITEM Foreground0;
CIT_SPAN_STAT_ITEM Foreground1;
CIT_SPAN_STAT_ITEM DisplayPower0;
CIT_SPAN_STAT_ITEM DisplayRequestChange;
CIT_SPAN_STAT_ITEM DisplayPower1;
CIT_SPAN_STAT_ITEM DisplayPower2;
CIT_SPAN_STAT_ITEM DisplayPower3;
CIT_SPAN_STAT_ITEM ContextFlushes1;
CIT_SPAN_STAT_ITEM Foreground2;
CIT_SPAN_STAT_ITEM ContextFlushes2;
} CIT_SYSTEM_DATA_SPAN_STATS;
typedef struct _CIT_USE_DATA_SPAN_STATS {
CIT_SPAN_STAT_ITEM ProcessCreation0;
CIT_SPAN_STAT_ITEM Foreground0;
CIT_SPAN_STAT_ITEM Foreground1;
CIT_SPAN_STAT_ITEM Foreground2;
CIT_SPAN_STAT_ITEM ProcessSuspended;
CIT_SPAN_STAT_ITEM ProcessCreation1;
} CIT_USE_DATA_SPAN_STATS;
typedef struct _CIT_SYSTEM_DATA_STATS {
WORD Unknown_BootIdRelated0;
WORD Unknown_BootIdRelated1;
WORD Unknown_BootIdRelated2;
WORD Unknown_BootIdRelated3;
WORD Unknown_BootIdRelated4;
WORD SessionConnects;
WORD ProcessForegroundChanges;
WORD ContextFlushes;
WORD MissingProgData;
WORD DesktopSwitches;
WORD WinlogonMessage;
WORD WinlogonLockHotkey;
WORD WinlogonLock;
WORD SessionDisconnects;
} CIT_SYSTEM_DATA_STATS;
typedef struct _CIT_USE_DATA_STATS {
WORD Crashes;
WORD ThreadGhostingChanges;
WORD Input;
WORD InputKeyboard;
WORD Unknown;
WORD InputTouch;
WORD InputHid;
WORD InputMouse;
WORD MouseLeftButton;
WORD MouseRightButton;
WORD MouseMiddleButton;
WORD MouseWheel;
} CIT_USE_DATA_STATS;
// PUU
typedef struct _CIT_POST_UPDATE_USE_INFO {
DWORD UpdateKey;
WORD UpdateCount;
WORD CrashCount;
WORD SessionCount;
WORD LogCount;
DWORD UserActiveDurationInS;
DWORD UserOrDispActiveDurationInS;
DWORD DesktopActiveDurationInS;
WORD Version;
WORD _Unk0;
WORD BootIdMin;
WORD BootIdMax;
DWORD PMUUKey;
DWORD SessionDurationInS;
DWORD SessionUptimeInS;
DWORD UserInputInS;
DWORD MouseInputInS;
DWORD KeyboardInputInS;
DWORD TouchInputInS;
DWORD PrecisionTouchpadInputInS;
DWORD InForegroundInS;
DWORD ForegroundSwitchCount;
DWORD UserActiveTransitionCount;
DWORD _Unk1;
FILETIME LogTimeStart;
QWORD CumulativeUserActiveDurationInS;
WORD UpdateCountAccumulationStarted;
WORD _Unk2;
DWORD BuildUserActiveDurationInS;
DWORD BuildNumber;
DWORD _UnkDeltaUserOrDispActiveDurationInS;
DWORD _UnkDeltaTime;
DWORD _Unk3;
} CIT_POST_UPDATE_USE_INFO;
// DP
typedef struct _CIT_DP_MEMOIZATION_ENTRY {
DWORD Unk0;
DWORD Unk1;
DWORD Unk2;
} CIT_DP_MEMOIZATION_ENTRY;
typedef struct _CIT_DP_MEMOIZATION_CONTEXT {
_CIT_DP_MEMOIZATION_ENTRY Entries[12];
} CIT_DP_MEMOIZATION_CONTEXT;
typedef struct _CIT_DP_DATA {
WORD Version;
WORD Size;
WORD LogCount;
WORD CrashCount;
DWORD SessionCount;
DWORD UpdateKey;
QWORD _Unk0;
FILETIME _UnkTime;
FILETIME LogTimeStart;
DWORD ForegroundDurations[11];
DWORD _Unk1;
_CIT_DP_MEMOIZATION_CONTEXT MemoizationContext;
} CIT_DP_DATA;
"""c_cit=cstruct.cstruct()c_cit.load(cit_def)classCIT:def__init__(self,buf):compressed_fh=io.BytesIO(buf)compressed_size,uncompressed_size=struct.unpack("<2I",compressed_fh.read(8))self.buf=lznt1_decompress(compressed_fh)self.header=c_cit.CIT_HEADER(self.buf)ifself.header.MajorVersion!=0x0A:raiseValueError("Unsupported CIT version")digest=crc32(self.buf[0x14:],crc32(self.buf[:0x10]))ifself.header.Crc32!=digest:raiseValueError("Crc32 mismatch")system_data_buf=self.data(self.header.SystemDataOffset,self.header.SystemDataSize,0x18)self.system_data=SystemData(self,c_cit.CIT_PERSISTED(system_data_buf))base_use_data_buf=self.data(self.header.BaseUseDataOffset,self.header.BaseUseDataSize,0x18)self.base_use_data=BaseUseData(self,c_cit.CIT_PERSISTED(base_use_data_buf))entry_data=self.buf[self.header.EntryDataOffset:]self.entries=[Entry(self,entry)forentryinc_cit.CIT_ENTRY[self.header.EntryCount](entry_data)]defdata(self,offset,size,expected_size=None):ifexpected_sizeandsize>expected_size:size=expected_sizedata=self.buf[offset:offset+size]ifexpected_sizeandsize<expected_size:data.ljust(expected_size,b"\x00")returndatadefiter_bitmap(self,bitmap:bytes):bit_delta=timedelta(seconds=self.header.BitPeriodInS)ts=wintimestamp(self.header.PeriodStartLocal)forbyteinbitmap:ifbyte==b"\x00":ts+=8*bit_deltaelse:forbitinrange(8):ifbyte&(1<<bit):yieldtsts+=bit_deltaclassEntry:def__init__(self,cit,entry):self.cit=citself.entry=entryprogram_buf=cit.data(entry.ProgramDataOffset,entry.ProgramDataSize,0x1C)self.program_data=c_cit.CIT_PROGRAM_DATA(program_buf)use_data_buf=cit.data(entry.UseDataOffset,entry.UseDataSize,0x18)self.use_data=ProgramUseData(cit,c_cit.CIT_PERSISTED(use_data_buf))self.file_path=Noneself.command_line=Noneifself.program_data.FilePathOffset:file_path_buf=cit.data(self.program_data.FilePathOffset,self.program_data.FilePathSize*2)self.file_path=file_path_buf.decode("utf-16-le")ifself.program_data.CommandLineOffset:command_line_buf=cit.data(self.program_data.CommandLineOffset,self.program_data.CommandLineSize*2)self.command_line=command_line_buf.decode("utf-16-le")def__repr__(self):returnf"<Entry file_path={self.file_path!r} command_line={self.command_line!r}>"classBaseUseData:MIN_BITMAPS_SIZE=0x8MIN_SPAN_STATS_SIZE=0x30MIN_STATS_SIZE=0x18def__init__(self,cit,entry):self.cit=citself.entry=entrybitmap_items=c_cit.CIT_BITMAP_ITEM[entry.BitmapsSize//len(c_cit.CIT_BITMAP_ITEM)](cit.data(entry.BitmapsOffset,entry.BitmapsSize,self.MIN_BITMAPS_SIZE))bitmaps=[cit.data(item.Offset,item.Size)foriteminbitmap_items]self.bitmaps=self._parse_bitmaps(bitmaps)self.span_stats=self._parse_span_stats(cit.data(entry.SpanStatsOffset,entry.SpanStatsSize,self.MIN_SPAN_STATS_SIZE))self.stats=self._parse_stats(cit.data(entry.StatsOffset,entry.StatsSize,self.MIN_STATS_SIZE))def_parse_bitmaps(self,bitmaps):returnBaseUseDataBitmaps(self.cit,bitmaps)def_parse_span_stats(self,span_stats_data):returnNonedef_parse_stats(self,stats_data):returnNoneclassBaseUseDataBitmaps:def__init__(self,cit,bitmaps):self.cit=citself._bitmaps=bitmapsdef_parse_bitmap(self,idx):returnlist(self.cit.iter_bitmap(self._bitmaps[idx]))classSystemData(BaseUseData):MIN_BITMAPS_SIZE=0x30MIN_SPAN_STATS_SIZE=0x58MIN_STATS_SIZE=0x1Cdef_parse_bitmaps(self,bitmaps):returnSystemDataBitmaps(self.cit,bitmaps)def_parse_span_stats(self,span_stats_data):returnc_cit.CIT_SYSTEM_DATA_SPAN_STATS(span_stats_data)def_parse_stats(self,stats_data):returnc_cit.CIT_SYSTEM_DATA_STATS(stats_data)classSystemDataBitmaps(BaseUseDataBitmaps):def__init__(self,cit,bitmaps):super().__init__(cit,bitmaps)self.display_power=self._parse_bitmap(0)self.display_request_change=self._parse_bitmap(1)self.input=self._parse_bitmap(2)self.input_touch=self._parse_bitmap(3)self.unknown=self._parse_bitmap(4)self.foreground=self._parse_bitmap(5)classProgramUseData(BaseUseData):def_parse_bitmaps(self,bitmaps):returnProgramDataBitmaps(self.cit,bitmaps)def_parse_span_stats(self,span_stats_data):returnc_cit.CIT_USE_DATA_SPAN_STATS(span_stats_data)def_parse_stats(self,stats_data):returnc_cit.CIT_USE_DATA_STATS(stats_data)classProgramDataBitmaps(BaseUseDataBitmaps):def__init__(self,cit,use_data):super().__init__(cit,use_data)self.foreground=self._parse_bitmap(0)# Some inlined utility functions for the purpose of the POCdefwintimestamp(ts,tzinfo=timezone.utc):# This is a slower method of calculating Windows timestamps, but works on both Windows and Unix platforms# Performance is not an issue for this POCreturndatetime(1970,1,1,tzinfo=tzinfo)+timedelta(seconds=float(ts)*1e-7-11644473600)# LZNT1 derived from https://github.com/google/rekall/blob/master/rekall-core/rekall/plugins/filesystems/lznt1.pydef_get_displacement(offset):"""Calculate the displacement."""result=0whileoffset>=0x10:offset>>=1result+=1returnresultDISPLACEMENT_TABLE=array.array("B",[_get_displacement(x)forxinrange(8192)])COMPRESSED_MASK=1<<15SIGNATURE_MASK=3<<12SIZE_MASK=(1<<12)-1TAG_MASKS=[(1<<i)foriinrange(0,8)]deflznt1_decompress(src):"""LZNT1 decompress from a file-like object.
Args:
src: File-like object to decompress from.
Returns:
bytes: The decompressed bytes.
"""offset=src.tell()src.seek(0,io.SEEK_END)size=src.tell()-offsetsrc.seek(offset)dst=io.BytesIO()whilesrc.tell()-offset<size:block_offset=src.tell()uncompressed_chunk_offset=dst.tell()block_header=struct.unpack("<H",src.read(2))[0]ifblock_header&SIGNATURE_MASK!=SIGNATURE_MASK:breakhsize=block_header&SIZE_MASKblock_end=block_offset+hsize+3ifblock_header&COMPRESSED_MASK:whilesrc.tell()<block_end:header=ord(src.read(1))formaskinTAG_MASKS:ifsrc.tell()>=block_end:breakifheader&mask:pointer=struct.unpack("<H",src.read(2))[0]displacement=DISPLACEMENT_TABLE[dst.tell()-uncompressed_chunk_offset-1]symbol_offset=(pointer>>(12-displacement))+1symbol_length=(pointer&(0xFFF>>displacement))+3dst.seek(-symbol_offset,io.SEEK_END)data=dst.read(symbol_length)# Pad the data to make it fit.if0<len(data)<symbol_length:data=data*(symbol_length//len(data)+1)data=data[:symbol_length]dst.seek(0,io.SEEK_END)dst.write(data)else:data=src.read(1)dst.write(data)else:# Block is not compresseddata=src.read(hsize+1)dst.write(data)result=dst.getvalue()returnresultdefprint_bitmap(name,bitmap,indent=8):print(f"{' '*indent}{name}:")forentryinbitmap:print(f"{' '*(indent+4)}{entry}")defprint_span_stats(span_stats,indent=8):forkey,valueinspan_stats._values.items():print(f"{' '*indent}{key}: {value.Count} times, {value.Duration}ms")defprint_stats(stats,indent=8):forkey,valueinstats._values.items():print(f"{' '*indent}{key}: {value}")defmain():parser=argparse.ArgumentParser()parser.add_argument("input",type=argparse.FileType("rb"),help="path to SOFTWARE hive file")parser.add_argument("--tz",default="UTC",help="timezone to use for parsing local timestamps")args=parser.parse_args()ifnotHAS_ZONEINFO:print("[!] zoneinfo module not available, falling back to UTC")tz=timezone.utcelse:tz=ZoneInfo(args.tz)hive=Registry.Registry(args.input)try:cit_key=hive.open("Microsoft\\Windows NT\\CurrentVersion\\AppCompatFlags\\CIT\\System")exceptRegistry.RegistryKeyNotFoundException:parser.exit("No CIT\\System key found in the hive specified!")forcit_valueincit_key.values():data=cit_value.value()iflen(data)<=8:continueprint(f"Parsing {cit_value.name()}")cit=CIT(data)print("Period start:",wintimestamp(cit.header.PeriodStartLocal,tz))print("Start time:",wintimestamp(cit.header.StartTimeLocal,tz))print("Current time:",wintimestamp(cit.header.CurrentTimeLocal,tz))print("Bit period in hours:",cit.header.BitPeriodInS//60//60)print("Aggregation period in hours:",cit.header.AggregationPeriodInS//60//60)print()print("System:")print(" Bitmaps:")print_bitmap("Display power",cit.system_data.bitmaps.display_power)print_bitmap("Display request change",cit.system_data.bitmaps.display_request_change)print_bitmap("Input",cit.system_data.bitmaps.input)print_bitmap("Input (touch)",cit.system_data.bitmaps.input_touch)print_bitmap("Unknown",cit.system_data.bitmaps.unknown)print_bitmap("Foreground",cit.system_data.bitmaps.foreground)print(" Span stats:")print_span_stats(cit.system_data.span_stats)print(" Stats:")print_stats(cit.system_data.stats)print()fori,entryinenumerate(cit.entries):print(f"Entry {i}:")print(" File path:",entry.file_path)print(" Command line:",entry.command_line)print(" PE TimeDateStamp",datetime.fromtimestamp(entry.program_data.PeTimeDateStamp,tz=timezone.utc))print(" PE CheckSum",hex(entry.program_data.PeCheckSum))print(" Extra 3:",entry.program_data.Extra3)print(" Bitmaps:")print_bitmap("Foreground",entry.use_data.bitmaps.foreground)print(" Span stats:")print_span_stats(entry.use_data.span_stats)print(" Stats:")print_stats(entry.use_data.stats)print()if__name__=="__main__":main()
Last week we were asked to perform incident response for a number of Conti ransomware cases. In one of these cases, a client’s entire ESXi infrastructure was encrypted with no backups available. After attempting to decrypt their data, they were still left with a lot of corrupt virtual machines. With no apparent solution, the client asked us to investigate data recovery options.
Before looking into data recovery options, we always take a look at the ransomware to see how it encrypts files and use that information to help focus our approach to data recovery. A brief look at the decrypter and the corrupt files revealed something interesting.
When Conti encrypts files, it writes a 512 byte RSA encrypted footer to the file. This piece of encrypted information contains the Chacha20 encryption key and nonce, the original file size and how and how much of the file was encrypted. Looking at the “corrupt” file, though, showed 1024 bytes of seemingly encrypted data.
Using the RSA key from the decrypter, we decrypted each piece of 512 bytes and indeed, both resulted in valid Conti file information. The second blob even states that the original file size was 512 bytes more than the first blob! Was it possible that the file wasn’t corrupted, but just still encrypted?
To test this theory, we renamed the file so it would be picked up by the decrypter. Repeating this once more indeed resulted in a fully intact original file! Given that our client had already run the decrypter on this file once, it meant that this file had been encrypted three times.
Using this information, we assisted the client in recovering all their broken files. And all in 30 minutes of effort!
This goes to show that oftentimes it’s worth looking just a little bit deeper at a problem. With very little effort we were able to help a client get back up and running in a situation that might otherwise have been catastrophic for them.